|
Currently I am an associate professor in Peng Cheng Laboratory (PCL), Shenzhen, China. I have received the Ph.D degree from the State Key Laboratory of Virtual Reality Technology and Systems, Beihang University, advised by Prof. Jia Li. I am the author of refereed journals and conferences such as TPAMI, TIP, CVPR and ICCV. Email: xiachq@pcl.ac.cn. |

|
|
I study computer vision and machine learning. My research lies much in image and video processing with learning and optimization methods.
|
|
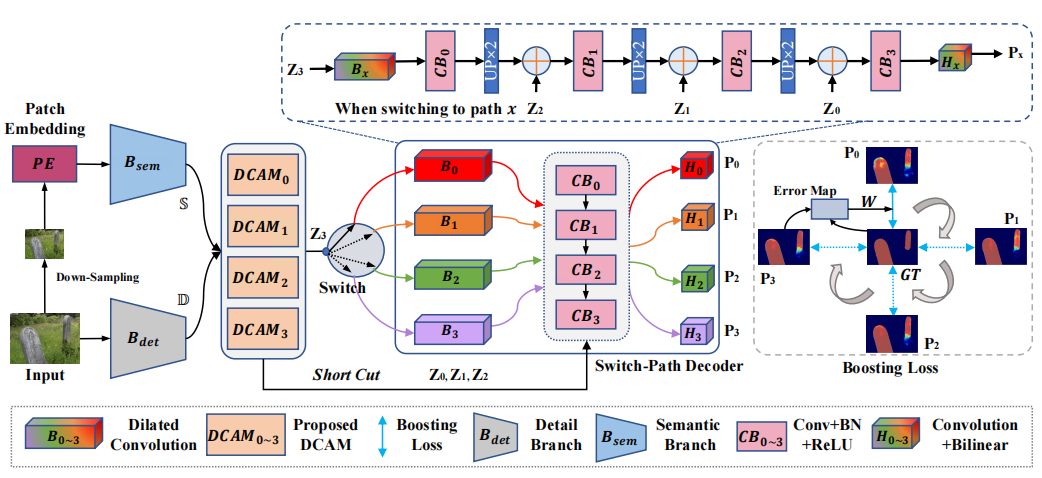
Mingcan Ma#, Changqun Xia#, Chenxi Xie, Xiaowu Chen, Jia Li TIP, 2023 paper / code We explore that it is difficult to segment large or small-scale objects due to their asymmetric segmentation requirements. We deconstruct the role of receptive fields in SOD and introduce a Bilateral Extreme Stripping encoder based on the simplified vision transformer and the lightweight CNN for the broader receptive fields. |

|
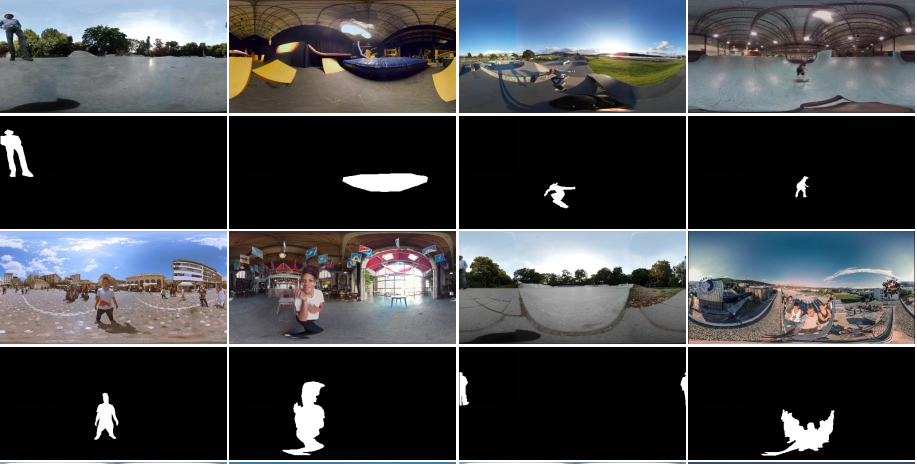
Junjie Wu, Changqun Xia*, Tianshu Yu, Jia Li TMM, 2022 paper / dataset We construct a 360 omnidirectional image-based SOD dataset, namely ODI-SOD. It has object-level pixelwise annotations on ERP images and is the largest dataset for 360 ISOD by far to our best knowledge. Moreover, we propose a view-aware salient object detection method for 360 ODIs. |

|
Chenxi Xie, Changqun Xia*, Mingcan Ma, Zhirui Zhao, Xiaowu Chen, Jia Li CVPR, 2022 paper / Project We contribute a new Ultra-High-Resolution Saliency Detection dataset UHRSD, containing 5920 images at 4K-8K resolutions. To our knowledge, it is the largest dataset in both quantity and resolution for high-resolution SOD task. We propose a novel one-stage framework called Pyramid Grafting Network. |

|
Jia Li, Jinming Su, Changqun Xia*, Mingcan Ma, Yonghong Tian TIP, 2021 paper / Project We rethink the two difficulties that hinder the development of salient object detection, which consists of indistinguishable regions and complex structures. To solve these two issues, we propose the purificatory network with structural similarity loss. |
|
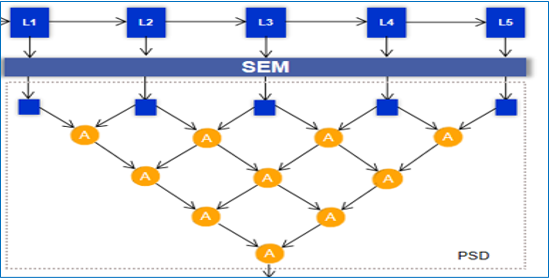
Mingcan Ma, Changqun Xia*, Jia Li AAAI, 2021 paper / project Existing methods usually aggregate the low-level features containing details and the high-level features containing semantics over a large span, which introduces noise into the aggregated features and generates inaccurate saliency maps. In this paper, we propose a pyramidal feature shrinking network. |
|
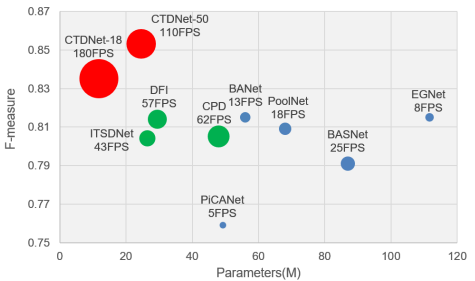
Zhirui Zhao, Changqun Xia*, Chenxi Xie, Jia Li ACM MM, 2021 (Oral Presentation) paper / code Most of existing SOD methods focus more on performance than efficiency. Besides, the U-shape structure exists some drawbacks and there is still a lot of room for improvement. Therefore, we propose a novel framework to treat semantic context, spatial detail and boundary information separately in the decoder part. |

|
Jinming Su, Changqun Xia*, Jia Li ICME, 2021 (Oral Presentation) paper Task-aware SOD has hardly been studied due to the lack of task-specific datasets. In this paper, we construct a driving task-oriented dataset where pixel-level masks of salient objects have been annotated. We proposed a baseline model for the driving task-aware SOD via a knowledge transfer convolutional neural network. |
|
Jia Li, Jinming Su, Changqun Xia*, Yonghong Tian JSTSP, 2020 paper / project SOD on 360 omnidirectional images is less studied owing to the lack of datasets with pixel-level annotations. Toward this end, this paper proposes a 360 image-based SOD dataset that contains 500 high-resolution equirectangular images. We proposes a baseline model for SOD on equirectangular images to deal with the distortion caused by the equirectangular projection. |

|
Jinming Su, Jia Li*, Yu Zhang, Changqun Xia, Yonghong Tian ICCV, 2019 paper / project Typically, a salient object detection (SOD) model faces opposite requirements in processing object interiors and boundaries. To address this selectivityinvariance dilemma, we propose a novel boundary-aware network with successive dilation for image-based SOD. |
|
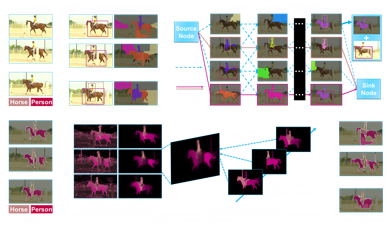
Yu Zhang, Xiaowu Chen, Jia Li, Chen Wang, Changqun Xia, Jun Li TPAMI, 2018 paper Extended version of CVPR 2015 with improved network flow solver and object shape prior. |
|
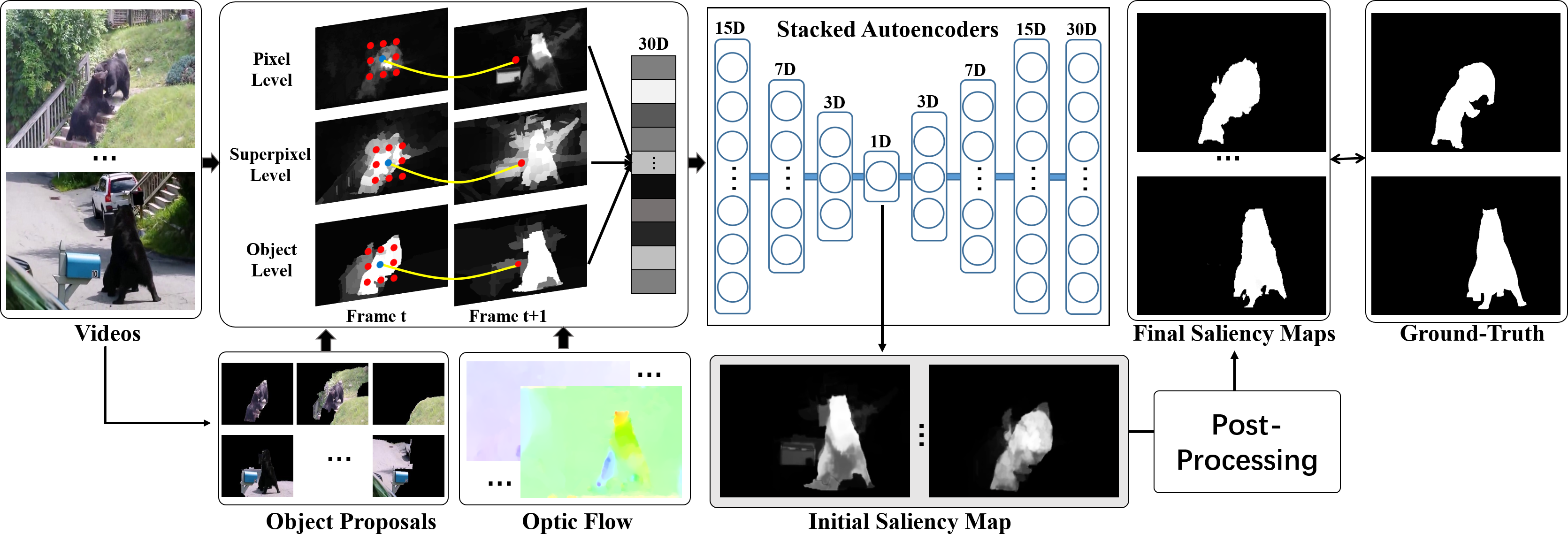
Jia Li, Changqun Xia, Xiaowu Chen TIP, 2018 paper / project video-based SOD is much less explored due to the lack of large-scale video datasets within which salient objects are unambiguously defined and annotated. Toward this end, this paper proposes a video-based SOD dataset that consists of 200 videos. Based on this dataset, this paper proposes an unsupervised baseline approach for video-based SOD by using saliency-guided stacked autoencoders. |

|
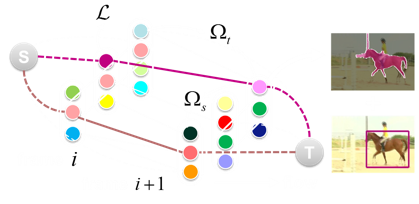
Changqun Xia, Jia Li, Xiaowu Chen, Anlin Zheng, Yu Zhang CVPR, 2017 paper / project Finding what is and what is not a salient object can be helpful in developing better features and models in salient object detection (SOD). In this paper, we investigate the images that are selected and discarded in constructing a new SOD dataset and find that many similar candidates, complex shape and low objectness are three main attributes of many non-salient objects. Then we propose a novel salient object detector by ensembling linear exemplar regressors. |
|
Yu Zhang, Xiaowu Chen, Jia Li, Chen Wang, Changqun Xia, CVPR, 2015 paper Weak object detectors can generate strong video object segmentation results via joint inference with a quadratic network flow model. |

|
Jia Li, Changqun Xia, Yafei Song, Shu Fang, Xiaowu Chen ICCV, 2015 paper / Video / Data / Code/ Existing metrics, which are often heuristically designed, may draw conflict conclusions in comparing saliency models. As a consequence, it becomes somehow confusing on the selection of metrics in comparing new models with state-of-the-arts. To address this problem, we propose a data-driven metric for comprehensive evaluation of saliency models. |

|
Changqun Xia, Jie Xu, Qing Li, Yu Zhang, Jia Li, Xiaowu Chen ICVRV, 2015 paper We propose an adaptive template for semantic labeling of indoor scene objects and estimating their oriented bounding facets (OBFs). The proposed adaptive template encodes prior geometric information of objects based on statistics of the training images. |
|
Much thanks to Jon Barron for sharing this template. |